🎉 The research on GreenViT has been successfully completed
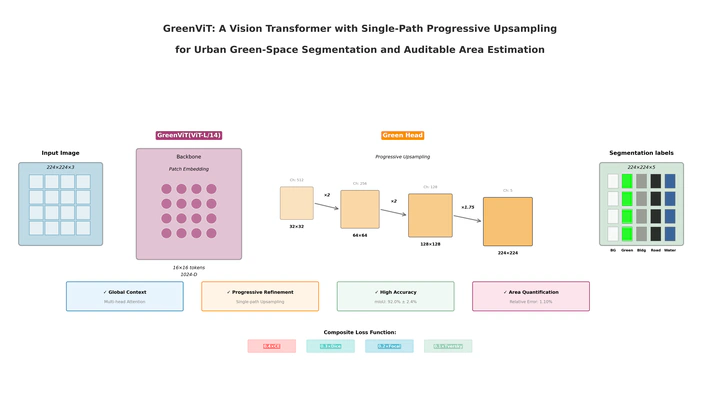 Image credit: Ziqiang Xu
Image credit: Ziqiang Xu🎉 Welcome 👋
Table of Contents
Research Background 📌
Urban green-space monitoring often suffers from an accuracy–efficiency trade-off and the lack of integrated, auditable area estimation. We present GreenViT—a ViT-L/14 backbone with a single-path progressive upsampling decoder (Green Head)—that preserves global context while recovering thin structures and converts pixel masks into physical areas. On five-fold evaluation, it achieves mIoU 0.9200±0.0243, Dice 0.9580±0.0135, PA 0.9570, with 1.10% relative error in area estimation.
Research Methodology 🔍
1️⃣ Single-Path Progressive Upsampling (Green Head)
- Starting from the 16×16 ViT token grid, we upsample by ×2, ×2, ×2, ×1.75 to 224×224 using lightweight blocks (1×1 reduce → 3×3 refine with BN+ReLU), without pyramid branches or skip concatenations—retaining ViT’s global field while stabilizing thin-structure recovery.
2️⃣ Fixed-Weight Composite Loss
- 0.4×CE + 0.3×Dice + 0.2×Focal(γ=2) + 0.1×Tversky(α=0.7, β=0.3) to handle class imbalance and sharpen boundaries.
3️⃣ Auditable Area Measurement
- An end-to-end pixel-to-physics calibration pipeline; at best checkpoints the relative area error is 1.10% (vs. 3.77% Swin-T; 6.73% SegFormer-B0).
4️⃣ Data Sampling & Augmentation
- TSliding-window sampling with 224 window and 112 stride for systematic coverage;
- Synchronized flips and ±5° rotations for images/labels, plus color jitter (0.1/0.1/0.1/0.05).
5️⃣ Unified Training Protocol
- AdamW + CosineAnnealingLR, 5-fold, unified early-stopping (PATIENCE=20) and sliding-window inference for fair comparisons with Swin-T / SegFormer-B0 / GreenViT+FPN.
Experimental Environment 💻
Hardware
GPU: NVIDIA GeForce RTX 3090
RAM: 128 GB
OS: Windows 11
Environment
Python 3.9
PyTorch 2.3.1
CUDA 11.8
OpenCV 4.10.0
⚠️ The project has been uploaded to GitHub, You can access the source code through this 👉GreenViT 🦄✨